In many hours of work and frustration I have learned that page segmentation and character models have a strong influence on the result of OCR. However, I always underestimated the effects of the initial step – the binarization.
Now I have looked at the binarization step more closely. Starting material are rather poor scans of the Austrian-Hungarian casualty lists. The scans themselves are not so bad. However, the paper is more than 100 years old and yellowed. There is a cutout:

Instead of looking at the binarization result directly or applying any kind of metric to it, I deceided to measure the final OCR result, i.e. the character accuracy. To avoid any problems during page segmentation I cut the two-column scans in half manually. Additionally I counted the detected lines. Since I used the same ground truth data for all measurements a missing/additional line would immediately be noticed by a very high error rate.
Typically ocropus-nlbin is used to create a bi-tonal image. As you can see the result is not very promissing. Maybe characters are eroded.

After running the page segmentation ocropus-gpagesep without additional parameters I noticed that some characters/words were eroded. By using the debug mode (-d option) you can see these holes in the line seeds:

With the --usegauss option that switches to a Gaussian kernel instead of a uniform kernel that problem can be avoided. But there was still another problem. Occasionally two lines were merged into one image. I also investiaged that problem using the debug mode. This is the relevant section:

The 7th and 8th line get merged. Apparently, the small red connection between the two lines is the cause of the merging. It seems as if the problem always occurs near white column separators. Therefore, I have to deactivate the detection of white column separators:
ocropus-gpageseg --csminheight 100000 --usegauss 0001.bin.png
Now the page separation works without problems and I can run the character prediction using my trained character model for the casualty lists.
As a different approach for binarization I have used ScanTailor, a program that has served me well in the past optimizing scans. By default ScanTailtor produces a 600dpi bi-tonal image from 300dpi gayscale input. It also allows the use the configure the threshold used for binarization. Although values from -50 to +50 are possible, for this example only values between 0 and +40 seem reasonable.
Finally, here are the results of my experiments:
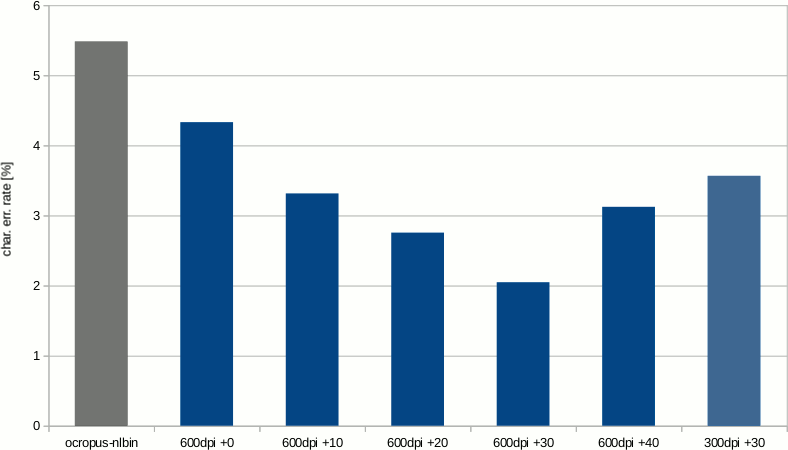
The bars in blue show the results of the ScanTailor binarization. The most right bar shows the effect the resolution of the bi-tonal image has. It is a 300dpi version with the best threshold setting determined for the 600dpi images.
As you can see, the binarization method used has a significant influence on the recognition quality. In my case the character recognition error is reduced by more than 60%.
You can find all images and ground truth data for this experiment on GitHub: https://github.com/jze/ocropus-binarization-experiment