One of the most underestimated programs for OCR (Optical Character Recognition) is OCRopus. The reason for this may lie in its sophisticated operation with several command line programs. You have to know the correct order to invoke the programs and the effects of OCRopus’ various options. You can achieve very good recognition rates (>99% correct characters) with OCRopus. However, you have to train a recognition model for your sources. A very good introduction to the use of OCRopus and the training of models is given in these two blog posts:
In this text I am going to focus on working with sources in table form. They are typical for official publications of the 19th and early 20th century such as statistics, registers, municipality lists etc. The printed tables are usually separated by vertical black lines. In combination with the lines (typically not separated by horizontal lines) they form table cells. Each table cell must be processed independently. Mixing content from neighboring cells will lead to bad results. Therefore, the detection of column separator is crucial.
The separation of the scan is done by ocropus-gpageseg. To detect vertical black lines as column separators you have to use the -b option. With the default setting only two vertical black lines will be recognized. The --maxseps option controls the number of detected black lines. When working with historical sources the lines are occasionally partial disconnected. In that case each line segment is counted as a black line. Therefore, you have to specify a much greater value for --maxseps.
Here is an example how the --maxseps effects the detection of column separators.
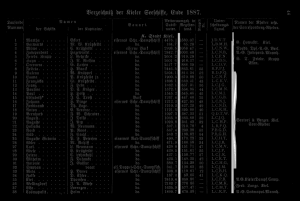
maxseps=2
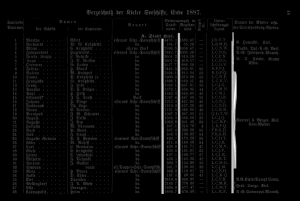
maxseps=3
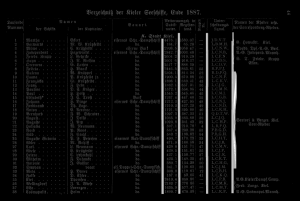
maxseps=4
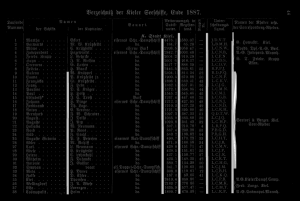
maxseps=5
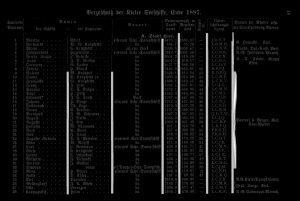
maxseps=6
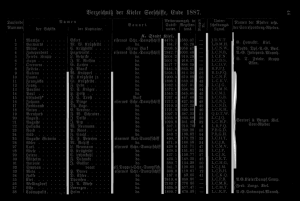
maxseps=7
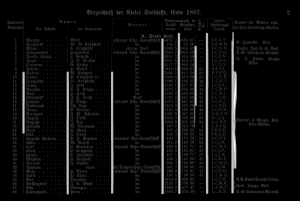
maxseps=8
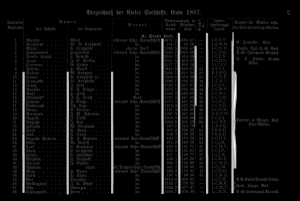
maxseps=9
The first four lines are detected perfectly. The 5th and 6th line are not detected completely. The 7th and 8th line are detected in the middle of the column separator. Step 9 shows the mentioned problem of partial disconnected lines. The first column separator is split in two lines. The lower part is detected later. However, the upper quarter has been completely overlooked. It is also interesting that 9 column separators are the maximum for this example. Even if you specify a greater value for --maxseps the missing parts of the column separators will not be recognized.
Sometimes the column detection does not work at all. Here is an example for such a case (the maxcols value has been set to 99 to void any limitation):

Maybe the column-spanning text block at the top confuses OCRopus’ algorithm. If you look very closely to the right border you can spot some detected vertical lines there. Does this dirt on the scan disturb the line detection? To check this, I manually crop the image.

Voilà, the center line is detected:

As you can see in this example, pre-processed cleaned scans are a prerequisite for good column detection results. Maybe the column detection algorithm can be optimized to deal with the quite common soiled scans.